中文互联网上一般搜素到的解决方案都是切换编码页。
但编码页不是Winodws PowerShell对中文字符乱码的真正原因。因为编码页只是针对不支持Unicode的程序采用的默认编码,按理说你的UTF8脚本不应该会采用这个编码页来读取。
实际问题出在Winodws PowerShell对UTF8的判断上,UTF-8标准形式是不带BOM的,但Windows下要带,Windows默认使用BOM来区分Unicode和非Unicode编码,对非Unicode就会使用程序指定的ANSI编码页来解读,而Unicode则会使用另一套称为宽字符的方法。老旧程序的本地化,一般都是编码页和语言&区域一起跟随着系统默认。这一套全球语言支持的方法在今天看起来是造成了很多不必要问题,但它成型太早了,那个时候很多相关的讨论还没有结果。
所以WinPS和CMD对UTF8文件的中文乱码,是因为它没有正确的识别这是一个UNICODE编码文件。如果你把脚本重新保存为带BOM的UTF8编码,脚本里的中文就能正确echo了。具体查看参考文档。实验参考下面的图片:
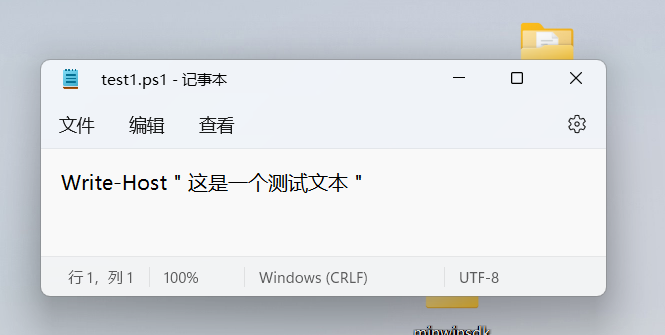
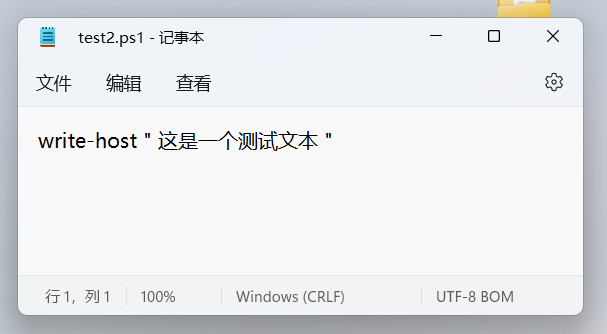
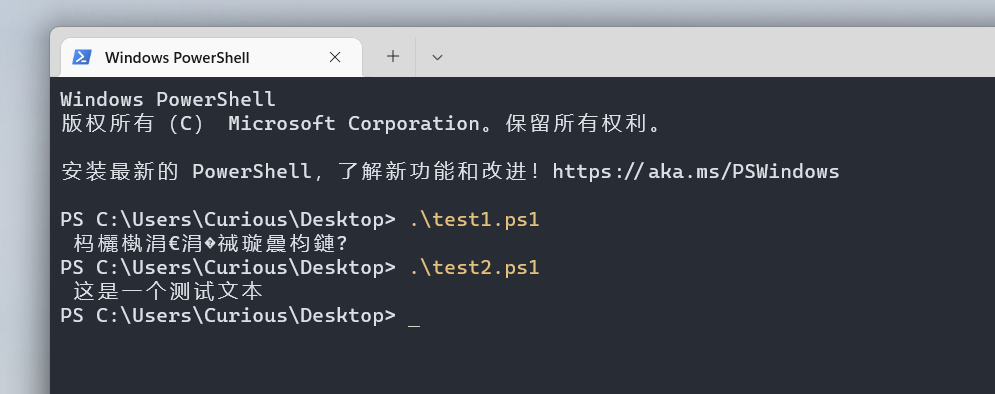
请注意高于6.0版本的PowerShell没这个问题,已经和主流处理方式保持一致了。无奈的是系统内置的还是不再更新的Windows PowerShell 5.1。
当然,切换本机编码页为UTF-8(实验性的)也可以解决这个问题,但如前文所说,这意味着放弃很多采用过时技术的软件的兼容性,除非你已经摆脱了那些不再更新的软件遗产,不然请谨慎考虑。或者,像随处可见的答案那样,为你的PowerShell指定编码页也可以——假如只有你自己用这些脚本的话。我们没办法保证别人的WinPS也采取了一样的配置。
因此,我建议读者Winodws PowerShell脚本使用UTF-8 BOM保存,而不是GB18030之类的兼容本地代码页的编码。原因是虽然PowerShell能正确识别本地代码页,但很多常用的代码编辑器打开脚本这类文件时却不能默认识别出来。所以还是用两者都能正确识别的UTF-8 BOM来编写你的WinPS脚本吧。
这同样不会毫无风险,假如你的脚本上传到一些Web环境中,在那里不带BOM的UTF-8是绝对标准。比如GitHub,带BOM的UTF-8文件会被解读为开头有一个奇怪的字符(变为可见)的UTF-8文档,虽然文本都能正常显示,但假如你在网页上直接编辑这些文件,并且不能像笔者一样熟谙编码的细节(笑😀),以至于不慎把这个碍眼的开头给删了,那么恭喜你,你再clone下来的文件编码格式就变成不带BOM的UTF-8了。没错,旧病复发。
听起来很绝望,但现实就是如此,事情总是不会很完美。这里有一篇文章帮助读者了解字符编码和Windows这部分处理的历史包袱。